1. 편리함 뒤에 숨은 성능의 늪
MRPD 프로젝트를 진행하며 외국인 사용자들을 위해 응답 데이터를 자동으로 번역해 주는 기능을 구현했습니다. @Translate 어노테이션만 붙이면 RestControllerAdvice가 이를 감지해 구글 번역 API를 호출하는 기능입니다.
하지만 실제 데이터를 돌려보는 순간, 서버 로그에는 끝도 없는 API 호출 기록이 찍히기 시작했습니다. 게시글 리스트 하나를 조회하는데 필드가 10개라면, 구글 API를 10번이나 호출하고 있었던 것입니다. 이것이 바로 N+1 문제의 시작이었습니다.
2. N+1 문제란 무엇인가?
N+1 문제는 ORM(객체-관계 매핑)을 사용할 때 하나의 요청으로 N개의 관련 데이터를 가져오려 하지만, 실제로는 1번의 기본 쿼리에 추가적으로 N번의 쿼리가 더 발생하여 총 N+1번의 쿼리가 실행되는 성능 비효율 현상을 말합니다. 흔히 JPA 조회 시 발생하는 것으로 알려져 있지만, 외부 API 호출 환경에서도 동일하게 발생하며 훨씬 더 치명적입니다.
- 정의: 1번의 쿼리(또는 요청)로 가져온 N개의 데이터를 처리하기 위해, 연관된 데이터를 가져오는 N번의 추가 요청이 발생하는 현상입니다.
- 스프링에서의 발생: 보통
Loop내부에서 서비스 로직을 호출할 때 발생합니다. 이번 프로젝트에서는 응답 객체의 필드를 하나씩 순회하며 번역 메서드를 호출한 것이 원인이었습니다. - 치명적인 이유: DB 쿼리는 내부 망 통신이라도 하지만, 구글 API 호출은 네트워크 오버헤드가 발생하며 호출당 **비용(Cost)**이 발생합니다. 데이터가 많아질수록 서버는 느려지고 지갑은 가벼워지는 구조였죠.
[Image of N+1 query problem visualization in Spring]
3. 개선 전: 필드별 개별 호출 (The Naive Way)
처음 구현한 방식은 필드 단위로 번역을 요청하는 ‘순진한’ 방식이었습니다.
기존 로직의 흐름
- 응답 객체의 필드를 리플렉션으로 순회한다.
@Translate가 붙은 필드를 찾는다.translationService.translate(text)를 호출한다. (내부에서 DB 조회 및 API 호출 발생)
// TranslationAdvice 내부 (개선 전)
for (Field field : targets) {
String text = (String) field.get(obj);
// 문제의 구간: 필드마다 DB와 API에 계속 노크를 함
String translated = translationService.translate(text, targetLang);
field.set(obj, translated);
}
이 방식은 게시글 20개를 조회할 때, 각 게시글에 번역 필드가 3개씩만 있어도 최대 60번의 API 호출이 발생할 수 있는 위험한 구조였습니다.
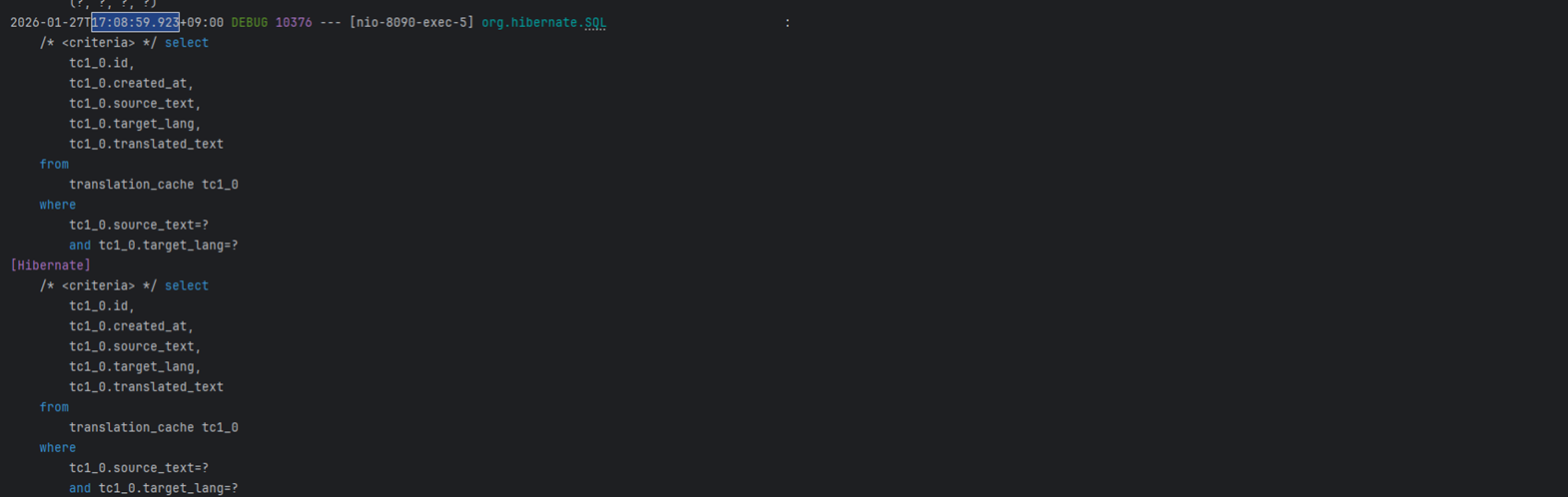
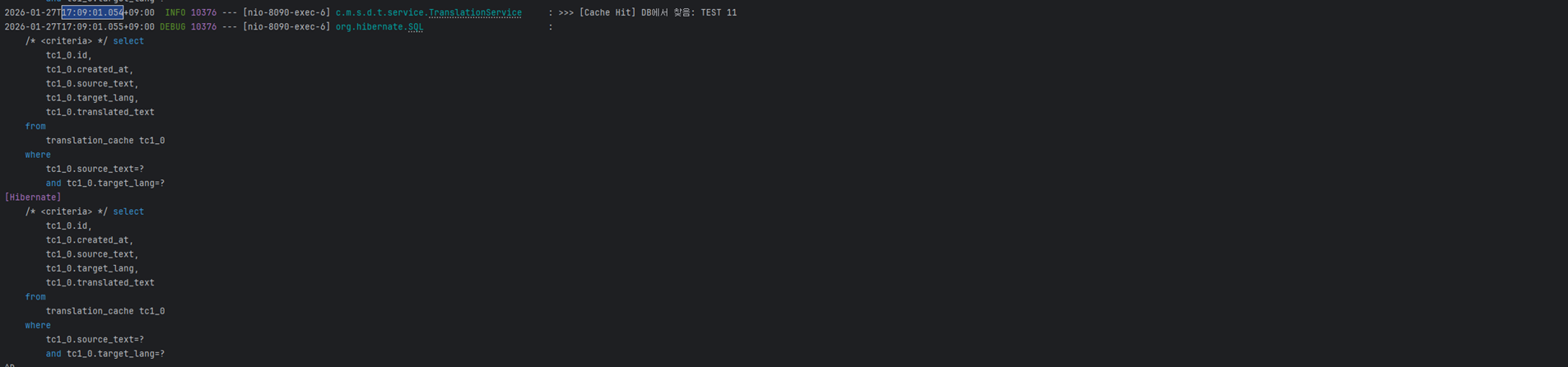
위 2개의 이미지를 보면 알 수 있듯이 개선 전은 약 1,131ms로 1.1초정도 걸리는 것을 확인할 수 있습니다.
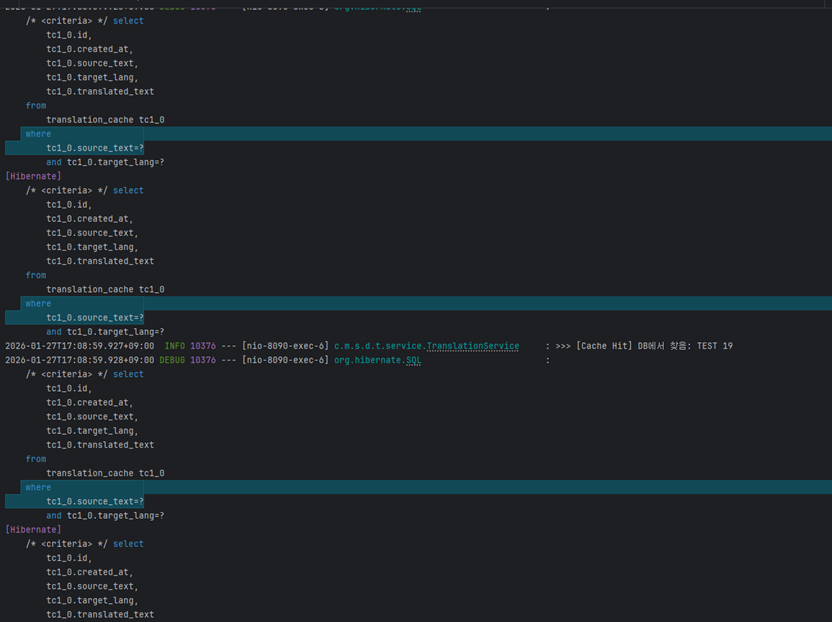
실행되는 쿼리 또한
where source tc1_0.source=text?로 쿼리 하나하나가 실행되는 것을 볼 수 있습니다. (30개의 게시글 = 30개의 쿼리 실행)
4. 해결 방법
이 문제를 해결하기 위해 번역 대상을 한꺼번에 모아서 처리하는 배치(Batch) 방식을 도입했습니다.
- 수집 : 응답 객체 내의 모든 번역 대상 텍스트를 중복 없이(Set) 한곳에 모읍니다.
- 일괄 조회 :
IN절을 사용하여 단 한번의 쿼리로 DB 캐시를 확인합니다.
public interface TranslationCacheRepository extends JpaRepository<TranslationCache, Long> {
List<TranslationCache> findBySourceTextInAndTargetLang(
Collection<String> sourceTexts, String targetLang);
}
- 일괄 번역 : 캐시에 없는 텍스트들만 모아 구글 API를 단 한 번 호출합니다.
- 매핑 : 번역된 결과 맵
(Map<Source, Translated>)을 사용하여 각 필드에 값을 할당합니다.
핵심 구현 코드
public Map<String, String> translateBulk(List<String> texts, String targetLang) {
Set<String> uniqueTexts = new HashSet<>(texts);
Map<String, String> resultMap = new HashMap<>();
List<TranslationCache> cachedItems = repository.findBySourceTextInAndTargetLang(uniqueTexts, targetLang);
cachedItems.forEach(item -> resultMap.put(item.getSourceText(), item.getTranslatedText()));
List<String> missingTexts = uniqueTexts.stream()
.filter(text -> !resultMap.containsKey(text))
.toList();
if (!missingTexts.isEmpty()) {
List<String> apiResults = callGoogleApiBulk(missingTexts, targetLang);
// 결과 저장 로직...
}
return resultMap;
}
실제로 테이블을 비운 후

위 핵심 코드로 적용하고 실행했을 때 다음과 같은 결과가 나온걸 확인할 수 있습니다.
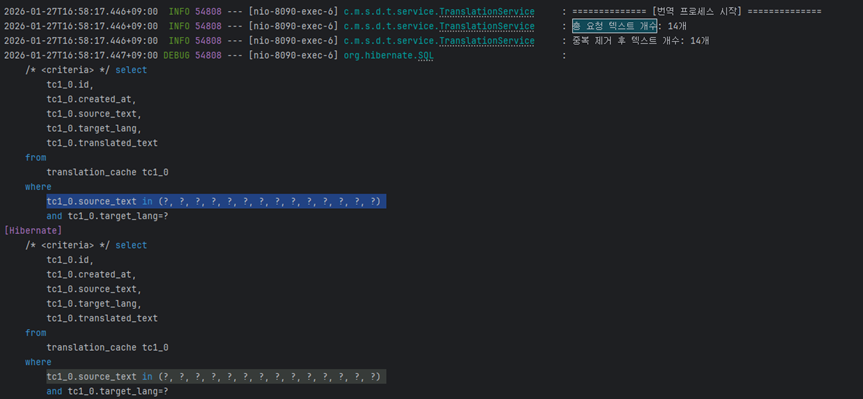
쿼리 또한 tc1_0.soruce_text in (?,?,?,?,? …. ?) 으로 단 하나의 쿼리로 실행되는것을 볼 수 있습니다. (Batch 방식 도입, N+1 문제 해결)
5. 개선 전 vs 개선 후
실제로 약 30개의 게시글을 넣은 후에 테스트를 진행 해보았을 때,
개선 전
DB 쿼리 횟수: 30회,네트워크 비용: 고비용,안정성: API 할당량 소모 빠름,실행 시간: 1,131ms
개선 후
DB 쿼리 횟수: 1회,네트워크 비용: 저비용(단일 왕복),안정성: 효율적 소모,실행 시간: 450ms
6 마치며.
N+1 문제는 Spring JPA에서 자주 발생하는 문제중 하나입니다. 이번 다국어 번역 시스템 기능을 구현하면서 외부 리소스(DB,API)와의 언제나 최후의 수단이여야 하며, 반드시 최소화해야 한다는 점입니다. N+1의 근본적인 개념을 짚고 나서, 문제 과정을 겪은 뒤 실제로 테스트 후 성능 개선까지 전반적으로 겪어보면서 또 하나의 기술적 경험을 얻었습니다.